 91天空 科技 生活 快乐
91天空 科技 生活 快乐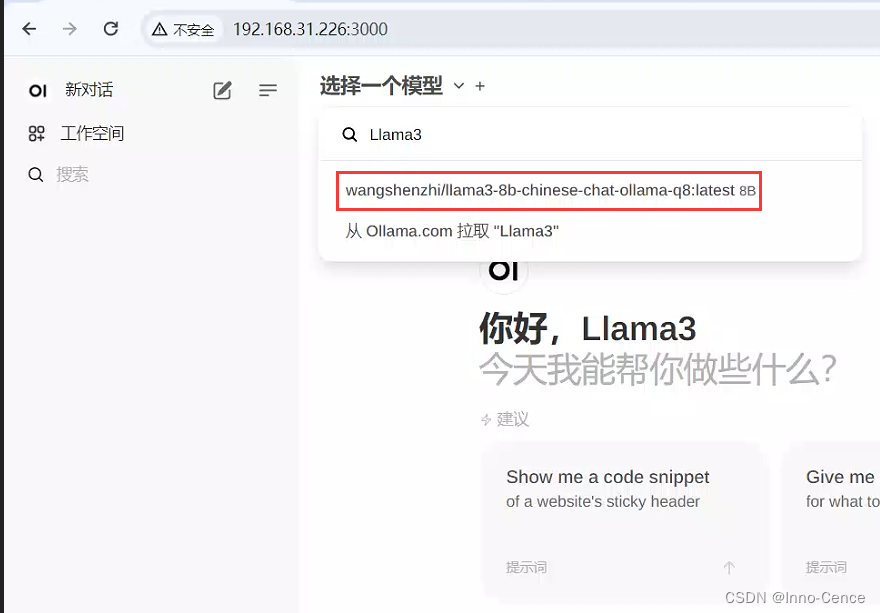
一、创建虚拟机
1.1按照常规的CentOS教程来安装就行,我用的是以下版本:
VMware版本:VMware Workstation Full v12.1.0-3272444 中文正式版
镜像版本:CentOS-7-x86_64-DVD-2009
1.2虚拟机配置参数,如下:
二、升级虚拟机必要组件功能
2.1运行以下命令可以更新系统中的所有安装的软件包至最新版本:
sudo yum update
注意:安装过程中会多次提示:“Is this ok [y/N]”: ,需要手动键入“y”,才能继续进程,后续安装过程同样会遇到这个提示,不会再赘述。
2.1更新系统软件包后,你可以使用以下命令来检查系统是否有需要的更新:
sudo yum check-update
2.2升级python3(建议按照自己的习惯升级)
这里举例我常用的升级命令:
sudo yum install epel-release
sudo yum install python3
sudo yum install python3-devel
sudo yum install python3-pip
python3 –version
三、安装Ollama
3.1安装Ollama的过程很费时间,几十分钟到大几个小时不等,安装命令如下:
curl -fsSL https://ollama.com/install.sh | sh
1000Mbps的光纤,蹲个坑回来下了这么点…屑。
四、部署Llama3-8B-Chinese-Chat-v2.1模型
4.1运行以下任意一条命令,可以最快速地部署对应版本的Llama3-8B-Chinese-Chat-v2.1模型:
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q4
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8
ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-fp16
模型的下载速度比较快,小十分钟就能下好。
模型的版本越高、文件越大、运算力越好、越吃性能,我装的是q8_0版本,这里有个q8_0模型在线版的url,安装过程中可以进去把玩一下(要翻墙):https://huggingface.co/spaces/llamafactory/Llama3-8B-Chinese-Chat
4.2部署完之后,就直接进入到对应大模型的命令行聊天界面了:
可以问它一些中英互译比较有歧义的问题,来测试它对中文的语言理解和生成能力,不深入演示了,CPU要被干烧了。
4.3通过ollama命令可以查看、运行、更新、复制、移除已部署的大模型。
4.3.1如:ollama list,可以查看虚拟机内已部署的大模型,可以看到我只安装了一款。
[llama3@Llama3 ~]$ ollama list
NAME ID SIZE MODIFIED
wangshenzhi/llama3-8b-chinese-chat-ollama-q8:latest 6739fd08efd6 8.5 GB 21 minutes ago
4.4.2如:ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8,运行指定大模型。
[llama3@Llama3 ~]$ ollama run wangshenzhi/llama3-8b-chinese-chat-ollama-q8
>>> Send a message (/? for help)
五、安装Open WebUI
Open WebUI是一个可拓展、功能丰富且用户友好的自托管 WebUI,旨在完全离线运行。它支持各种 LLM 运行器,包括Ollama和OpenAI 兼容API。简单地说就是给大模型提供一个图形化界面,以及生成一个API,后续就可以通过特定的IP+端口号在浏览器登陆大模型了。
5.1先安装Docker,按照自己的习惯安装就行,以下是我常用的命令:
sudo yum install -y yum-utils
sudo yum-config-manager –add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
sudo yum install docker-ce
sudo systemctl start docker
sudo systemctl enable docker
docker –version
5.2使用默认配置进行安装(要下载很久,几个小时到十几个小时不等),命令如下:
docker run -d -p 3000:8080 –add-host=host.docker.internal:host-gateway -v open-webui:/app/backend/data –name open-webui –restart always ghcr.io/open-webui/open-webui:main
挂一天一夜,基本上能下完。
安装完之后,可以用命令看进程,看到WebUI是运行在docker容器之上的。
[root@Llama3 ~]# docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
9bbab31dcda6 ghcr.io/open-webui/open-webui:main “bash start.sh” 15 hours ago Up 15 hours (healthy) 0.0.0.0:3000->8080/tcp, :::3000->8080/tcp open-webui
5.3安装后,就可以通过http://localhost:3000访问Open WebUI了(localhost就是虚拟机的ip),如果虚拟机改了ip的话,可用新ip无缝衔接登陆。
进去先注册账号,无需联网,相当于注册一个管理员账号。
语言可以设置成中文。
5.4刷新Ollama,测试一下到Ollama服务器的连通信。
5.4.1部署成功的话,应该提示:“已验证服务器连接性”。
5.4.2提示:“WebUI could not connect to Ollama”,证明从Open WebUI界面访问Ollama时遇到了困难,排查思路单独放在第六小节。
5.2加载自己已安装的模型,或者在线下载想要的模型。
我已经安装过wangshenzhi/llama3-8b-chinese-chat-ollama-q8模型了,所以这里可以直接加载出来(忽略第四步,在这里直接在线拉取模型到本地,其实是可以的)。
5.3将常用的模型设为默认即可,用前面注册的账号可以离线登录,并保留每次的对话记录。
六、WebUI could not connect to Ollama排查思路
如果您在从 Open WebUI 界面访问 Ollama 时遇到困难,这可能是因为 Ollama 默认配置为侦听受限网络接口。要启用从 Open WebUI 的访问,您需要将 Ollama 配置为侦听更广泛的网络接口。
6.1通过调用来编辑systemd服务,打开一个编辑器:
systemctl edit ollama.service
6.2Environment对于每个环境变量,在部分下添加一行[Service]:
记得“ESC”、“:wq”,保存并退出。
[Service]
Environment=”OLLAMA_HOST=0.0.0.0″
6.3重新加载systemd并重新启动Ollama:
systemctl daemon-reload
systemctl restart ollama
6.4刷新一下Ollama API,显示以下画面就可以回去第五节看看了。
未经允许不得转载:91天空 科技 生活 快乐 » 在CentOS7虚拟机上使用Ollama本地部署Llama3大模型中文版+Open WebUI#转载
 SOZEER – 新一代智能AI搜索引擎正式发布!V1.0.0
SOZEER – 新一代智能AI搜索引擎正式发布!V1.0.0
 叛乱:沙漠风暴开服攻略 windows+linux
叛乱:沙漠风暴开服攻略 windows+linux Excel连接DeepSeek的完美结合
Excel连接DeepSeek的完美结合 Windows 11 微软 Recall 召回功能有重大安全隐患!如何检测并禁用?
Windows 11 微软 Recall 召回功能有重大安全隐患!如何检测并禁用?