 91天空 科技 生活 快乐
91天空 科技 生活 快乐Meta 公司昨日(9 月 25 日)发布博文,正式推出了 Llama 3.2 AI 模型,其特点是开放和可定制,开发者可以根据其需求定制实现边缘人工智能和视觉革命。
Llama 3.2 提供了多模态视觉和轻量级模型,代表了 Meta 在大型语言模型(LLMs)方面的最新进展,在各种使用案例中提供了更强大的功能和更广泛的适用性。
其中包括适合边缘和移动设备的中小型视觉 LLMs (11B 和 90B),以及轻量级纯文本模型(1B 和 3B),此外提供预训练和指令微调(instruction-tuned)版本。
-
Llama 3.2 90B Vision(文本 + 图像输入):Meta 最先进的模型,是企业级应用的理想选择。该模型擅长常识、长文本生成、多语言翻译、编码、数学和高级推理。它还引入了图像推理功能,可以完成图像理解和视觉推理任务。该模型非常适合以下用例:图像标题、图像文本检索、视觉基础、视觉问题解答和视觉推理,以及文档视觉问题解答。
-
Llama 3.2 11B Vision(文本 + 图像输入):非常适合内容创建、对话式人工智能、语言理解和需要视觉推理的企业应用。该模型在文本摘要、情感分析、代码生成和执行指令方面表现出色,并增加了图像推理能力。该模型的用例与 90B 版本类似:图像标题、图像文本检索、视觉基础、视觉问题解答和视觉推理,以及文档视觉问题解答。
-
Llama 3.2 3B(文本输入):专为需要低延迟推理和有限计算资源的应用而设计。它擅长文本摘要、分类和语言翻译任务。该模型非常适合以下用例:移动人工智能写作助手和客户服务应用。
-
Llama 3.2 1B(文本输入):Llama 3.2 模型系列中最轻量级的模型,非常适合边缘设备和移动应用程序的检索和摘要。该模型非常适合以下用例:个人信息管理和多语言知识检索。
其中 Llama 3.2 1B 和 3B 模型支持 128K 标记的上下文长度,在边缘本地运行的设备用例(如摘要、指令跟踪和重写任务)中处于领先地位。这些模型在第一天就支持高通和联发科硬件,并针对 Arm 处理器进行了优化。

安装步骤:
1、通过Ollama进行部署 ,支持多平台!Windows / Mac /Linux 都可以运行 【点击下载】
并在 Windows 上打开 WSL 功能:
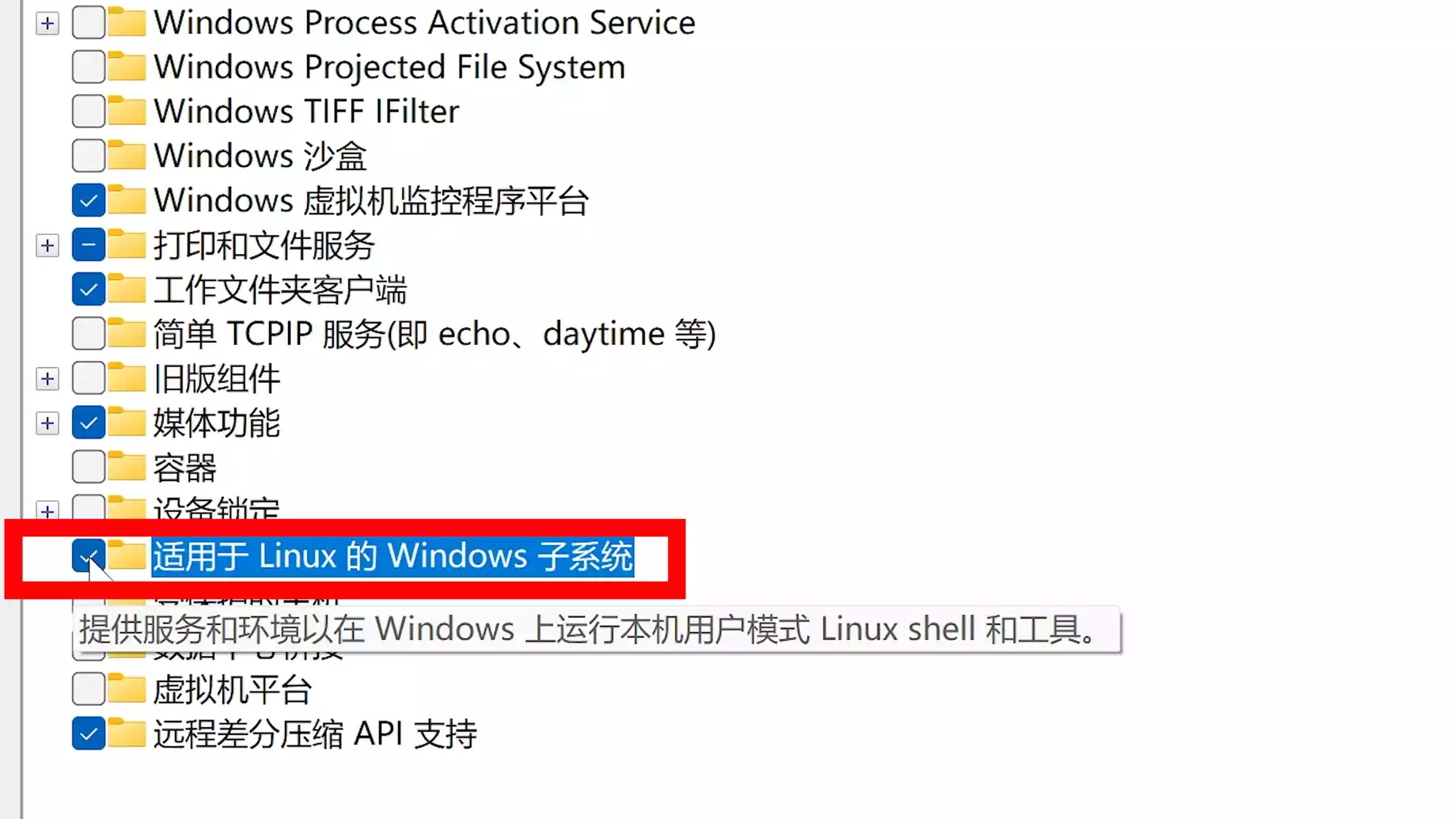
2、安装Docker Desktop :【点击前往】
然后本地安装webUI
(1)在CPU下运行:
(2)支持GPU运行:
安装完成通过本地地址:http://127.0.0.1:3000 进行访问,然后在里面下载安装Llama 3.2 模型

Llama 3.2 11B 本地部署教程:
注意:11B模型 需要22G以上的显存才能运行
Llama 3.2 11B 视觉模型下载方式
1、Hugging Face下载:【点击前往】 从模型库下载Llama 3.2 11B的模型文件。模型文件可以通过API或者手动下载。
2、其它打包下载:【点击前往】
1. 安装Python和pip
首先,确保你已经安装了Python 3.8或以上版本。如果还没有,可以通过以下步骤安装。
下载Python:
从Python官网下载适用于Windows的最新版本Python。安装时,确保勾选“Add Python to PATH”选项,以便命令行可以直接使用Python。
检查Python和pip是否安装成功:
如果成功,会显示Python和pip的版本号。
2. 安装CUDA和PyTorch
比如使用 RTX 4090进行加速,需要安装支持CUDA的PyTorch版本。
安装CUDA
- 下载并安装CUDA工具包(确保与你的显卡型号兼容)。
- 安装NVIDIA cuDNN(CUDA的深度学习库)。
安装支持CUDA的PyTorch:
打开命令提示符并运行以下命令,安装支持CUDA 11.8的PyTorch:
这会安装带有GPU加速功能的PyTorch版本,确保充分利用RTX 4090的计算性能。
3. 安装Llama 3.2 11B模型相关依赖
接下来,你需要安装Transformers库以及其他依赖项,用来加载Llama 3.2模型。
安装Transformers和其他依赖:
4. 下载和配置Llama 3.2 11B模型
1、从Hugging Face模型库下载Llama 3.2 11B的模型文件。模型文件可以通过API或者手动下载。
加载Llama 3.2 11B模型
你可以使用以下代码下载并加载模型:
请确保将path_to_llama_3_2_11b_model替换为实际的模型路径或模型ID。
5. 安装Gradio并创建UI
安装Gradio
创建Gradio界面
在Windows系统上,你可以创建一个Gradio界面,让用户可以通过浏览器与Llama 3.2 11B模型交互:
6. 启动Gradio应用
保存上面的脚本为 llama_gradio_app.py,然后在命令提示符中运行以下命令:
Gradio将在命令行中生成一个URL,你可以通过这个URL在浏览器中访问Gradio界面,并与Llama 3.2 11B模型进行交互。
7. 可选优化
- GPU加速:确保模型在GPU上运行。你可以通过以下代码将模型加载到GPU中:
调优生成结果:可以通过修改generate函数中的max_length参数来控制生成文本的长度。
当然如果你不想本地部署安装,或者显卡不支持,也可以直接在线体验 !
Llama 3.2 11B在线使用:【点击前往】 支持图片识别功能
未经允许不得转载:91天空 科技 生活 快乐 » 本地部署安装 Llama 3.2 大模型,支持1B、3B、11B、90B 模型
 SOZEER – 新一代智能AI搜索引擎正式发布!V1.0.0
SOZEER – 新一代智能AI搜索引擎正式发布!V1.0.0
 叛乱:沙漠风暴开服攻略 windows+linux
叛乱:沙漠风暴开服攻略 windows+linux Excel连接DeepSeek的完美结合
Excel连接DeepSeek的完美结合 Windows 11 微软 Recall 召回功能有重大安全隐患!如何检测并禁用?
Windows 11 微软 Recall 召回功能有重大安全隐患!如何检测并禁用?